

Indexers on Solana: Why Blockchain Data Isn’t as Simple as It Seems
Wed, Dec 17, 2025 •12 min read
I guess we all know someone who never remembers anniversaries, birthdays, or any important dates. I have to honestly admit that I am that person, which is why I rely on calendars and notes apps to keep everything organized, set reminders, and quickly find whatever information I need.
Now, let’s put that simple solution to my issue into a blockchain context. A blockchain is a public, distributed ledger in which data is linked together using cryptographic hashes. You might imagine it as one giant list of dates and records, like storing your whole family’s birthdays in one place. The problem is, it doesn’t give you a straightforward way to ask, e.g., for only the birthdays happening this month.
That’s the fundamental misunderstanding people have about blockchains.
The Misconception: “Blockchain = Queryable Database”
Imagine you’re running a company and want to give birthday bonuses to employees who’ve been with you for over 5 years, but only if their birthday falls this month. On a blockchain, it’s easy to prove something basic, like:
“I employ Alice, Bob, and John.”
But asking a more practical question is a whole different story:
“Show me all employees with over 5 years of tenure whose birthdays are this month.”
And here’s the catch: many people assume blockchains behave like normal searchable databases. They don’t. A blockchain is an append-only log, fantastic for storing and verifying transactions, terrible for querying them. Nodes return raw bytes and unindexed logs. Even simple questions may require scanning through thousands of transactions manually.
That’s why we need indexers.
Indexers turn low-level, unstructured data into clean, queryable information so applications can answer questions in milliseconds instead of minutes.
Indexers
Every blockchain works differently, so there’s no universal, magical solution for indexing data. Even within a single ecosystem, like Solana, multiple approaches exist, each with unique trade-offs.
So let's stay here for a moment and take Solana as an example and a case study. Why? Because Solana processes thousands of transactions per second (TPS) (btw if you’re interested in how many exactly, take a look here), and each one hides meaning inside opaque instruction bytes that every program decodes differently: SPL Token, Metaplex, various DEXes, custom programs, you name it.
What you want to extract also varies depending on your use case:
- real-time alerts
- deep historical analytics
- simple token tracking
Each of these demands a different strategy. This is why we don’t have a single "one tool to rule them all." There’s a natural trade-off triangle between:
- speed to market
- depth of customization
- operational complexity
No tool maximizes all three, so the ecosystem evolved into a toolbox of specialized indexers tailored for different jobs.
Indexers Overview
Below is a synthesized comparison of the most widely used Solana indexing solutions.
| Solution | Type | Best For | Complexity | Cost Model | Latency | Solana Maturity |
|---|---|---|---|---|---|---|
| Helius | Managed API | Fast MVPs, common use cases | ⭐ Low | Usage-based | Low (200-500ms) | ⭐⭐⭐⭐⭐ Excellent |
| Subsquid | Hybrid framework | Custom programs, analytics | ⭐⭐ Medium | Infra + compute | Medium (1-3s) | ⭐⭐⭐ Good |
| Substreams | Parallel ETL | High-throughput backfill | ⭐⭐⭐ High | Infra + Firehose | Low/Medium (1-2s) | ⭐⭐ Emerging |
| Geyser Plugin | Custom streaming | Ultra-low latency, full control | ⭐⭐⭐⭐⭐ Very high | Node + infra | Very low (<100ms) | ⭐⭐⭐⭐ Mature |
Quick Overview of Each
Managed APIs (Helius)
Plug-and-play indexing for tokens, NFTs, and wallets - with zero DevOps. Perfect for teams that need to ship fast. The trade-off: limited customization and vendor lock-in.
Hybrid Frameworks (Subsquid)
A middle-ground solution. You write custom decoding logic in TypeScript, backed by decentralized archives and GraphQL APIs. Great for analytics without heavy infra work.
Parallel ETL Pipelines (Substreams)
The high-horsepower option. Rust WASM modules process historical data in parallel, enabling massive backfills at extreme speed. Requires Rust skill and Firehose infra.
Custom Streaming (Geyser Plugins)
Ultra-low latency, full control. You tap directly into a validator to stream account updates in under 100ms. Ideal for stuff like HFT or compliance systems, but you must run full nodes and streaming infra like Kafka.
Case Study: Substreams
Imagine trying to understand everything happening on Solana. It’s like standing in front of a conveyor belt that never stops - boxes flying past, most of them are irrelevant, and you’re looking for just the one. The beauty of Substreams is that it transforms this chaos into clean, structured data using sinks. As the docs say, Sinks are integrations that allow you to send the extracted data to different destinations, such as a SQL database or a file.
Let’s say you want your results in a JSON file. Here’s how Substreams turns a torrent of data into a tidy output.json.

Substreams: A Step-by-Step Walkthrough
1. Solana Blockchain - The Raw Stream
Every ~400ms, Solana produces a block filled with everything: votes, transfers, swaps, and random program calls. No order, no filtering.
2. Firehose - Capture Everything First
Firehose nodes collect all chain data; it’s like downloading the entire chat history, not just unread messages.
3. Substreams Loads Your Config
Your substreams.yaml (the Substreams manifest) tells the engine exactly which modules to run and how data should flow. For example, by enabling solana:blocks_without_votes, you instantly strip away a massive amount of “background noise” before your code even sees the data.
In simple terms, the manifest is a YAML configuration file that defines your Substreams pipeline: what goes in, which modules process it, and what comes out. It can, for instance, take a raw blockchain block (like sf.ethereum.type.v2.Block) and transform it into a clean, custom output type (such as eth.example.MyBlock).
Code example:
modules:
- name: map_block
kind: map
initialBlock: 12287507
inputs:
- source: sf.ethereum.type.v2.Block
output:
type: proto:eth.example.MyBlock
4. Infrastructure Filter
This built-in module strips out vote transactions before your code runs.
100 total transactions
↓ remove vote txs
≈ 20 remain
5. Write Your Custom Logic
Now you apply your rules:
- Does this involve the MOFT token?
- Is the Token Program used?
- Does the instruction match what you need?
Your custom rules are written as a Substream module in a Rust function that receives an input and returns an output. For example, the following Rust function receives an Ethereum block and returns a custom object containing fields such as block number, hash, or parent hash.
fn get_my_block(blk: Block) -> Result<MyBlock, substreams::errors::Error> {
let header = blk.header.as_ref().unwrap();
Ok(MyBlock {
number: blk.number,
hash: Hex::encode(&blk.hash),
parent_hash: Hex::encode(&header.parent_hash),
})
}
6. Your WASM Module
Your custom logic is set in the Substreams Manifest as the path to the .wasm file built from the Rust function. E.g. map_my_data function receives only the filtered transactions, not the full firehose.
20 filtered transactions
↓ apply rules
1 match
7. Substreams Converts Output to JSON
Your protobuf schema is automatically serialized into JSON.
8. Final Output
You get a clean, ready-to-use output.json.
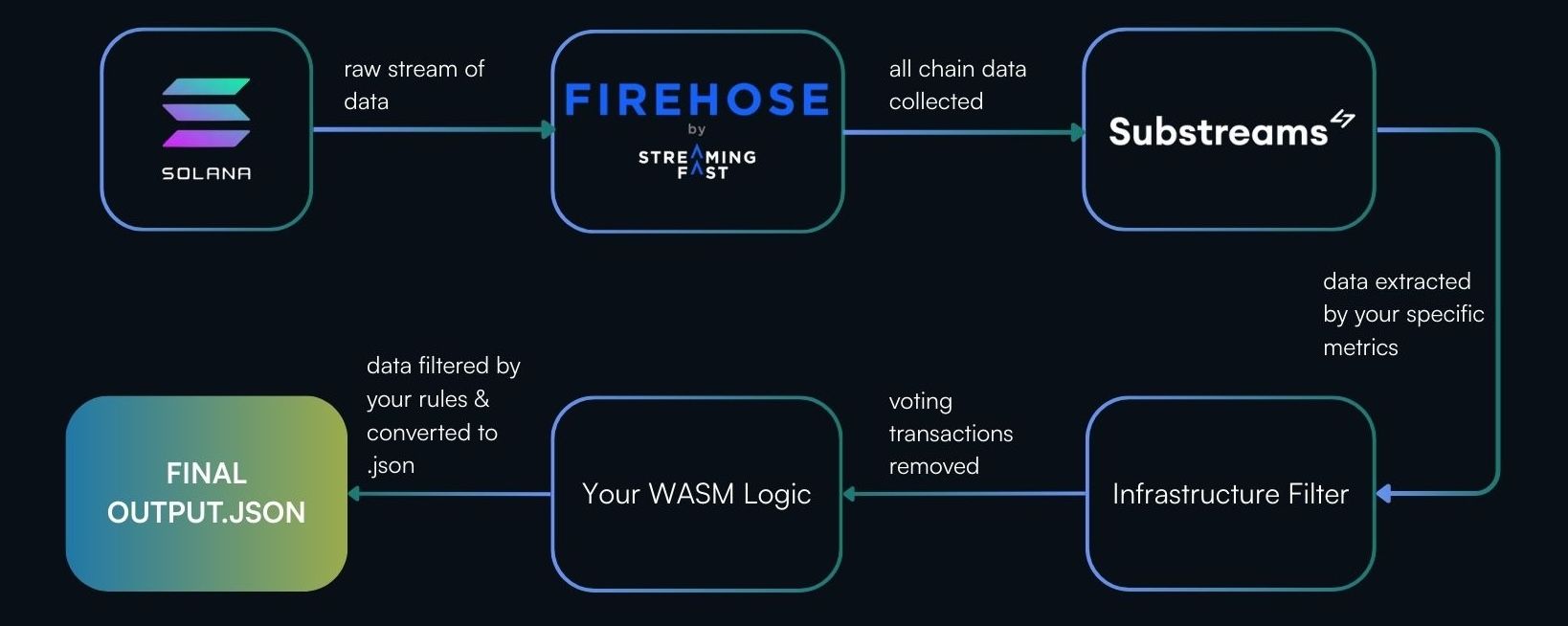
Recap:
→ Raw block (100 txs)
→ Firehose captures everything
→ Substreams loads config
→ Vote txs removed → 20 left
→ Your logic → 1 match
→ Convert to JSON
→ Save to output.json
Key Takeaways
Substreams works because it uses two layers of filtering:
- The system removes broad noise
- Your code extracts the precise data you need
It turns chain data from a warehouse search into opening a mailbox with only the letters you care about.
Case Study: Helius
Helius provides the APIs and infrastructure needed to build production-ready Solana applications. Their data streaming system lets applications receive real-time on-chain updates without polling.
As the docs put it, Data streaming allows applications to receive real-time updates from the Solana blockchain as events occur on-chain. Instead of repeatedly polling for updates, streaming establishes persistent connections that push data to your application instantly when transactions are processed, accounts change, or blocks are produced.
Now, let’s examine how Helius enables indexing through a clean, predictable pipeline.
How the Helius Indexer Pipeline Works
The pipeline has two lanes, historical and real-time, but both pass through the same parser before landing in PostgreSQL.

Helius: A Step-by-Step Walkthrough
1. Solana Blockchain → Helius API
Solana emits raw transactions - SOL transfers, SPL token activity, CPI-heavy program calls.
Helius exposes this data through:
- Batch endpoints (for historical backfills)
- Webhooks (for real-time updates)
This gives you structured data without running a validator.
2. Backfill Worker (Historical Processing)
Your archive crawler:
- Fetches signatures (100 at a time)
- Retrieves full transactions in batches of 25
- Parses all instructions and CPIs
- Extracts SOL transfers, token transfers, mints, and burns
- Writes everything to PostgreSQL
- Tracks progress to resume safely
Purpose: rebuild the full historical data you need.
3. Webhook Worker (Real-Time Updates)
Handles the live stream:
- Receives new transactions within ~2–3 seconds
- Uses the same parsing logic as the backfill
- Writes new data into the same tables
Purpose: keep your database continuously synced with the chain.
4. Unified Transaction Parser
Both workers rely on one parsing module that:
- Identifies program IDs
- Handles System Program, Token Program, and your custom programs
- Decodes CPIs
- Normalizes results into structured records
Purpose: convert chaotic transaction logs into clean SQL rows.
5. PostgreSQL Storage
Data is stored across three important tables:
- transfers → all token & SOL movements
- program_events → custom program interactions
- ingestion_state → backfill checkpoint tracking
Purpose: provide a stable, analytics-ready schema.
Key Takeaways
- Two lanes of ingestion → backfill (past) + webhooks (present)
- One unified parser → consistent data across time
- CPI-aware logic → captures what programs actually do
- Resumable backfill → no missing or duplicated data
- SQL-first design → fast queries, dashboards, and analytics
This architecture gives you an end-to-end indexing pipeline, from raw on-chain activity to fully structured records, without maintaining your own validator.
Indexers on Solana: A Summary
I hope it’s clear now that working with blockchain data isn’t as straightforward as it seems at first glance. We walked through two popular indexing approaches, Substreams and Helius, each optimized for different needs. This is not the only way to handle blockchain data, of course. My goal here was simply to show what’s possible, highlight the trade-offs, and encourage you to explore further.
As always: do your own research, experiment, and choose the right tool for your use case. And don’t forget to index the results of your digging, so you can actually use them quickly and without pain. No need to thank me. Cheers!

Oskar Karcz
Blockchain Developer & Content Guru
Recent posts







