

How to perform time-restricted iterations over Big Data with AWS Step Functions
Tue, May 17, 2022 •8 min read
Today’s blog post demonstrates the most efficient way of iterating over a huge dataset when every record needs to be updated within a restricted time frame. This requirement might be applied when you rely on calls to an external service and the number of requests per day is capped, or when you’re careful about the number of resources you use in order to prevent a “denial service attack” upon yourself. In any case, it’s good to know which tools work best with big databases and how to use them to save yourself time and resources.
Let’s set the stage with some base code
In a very straight-forward way of thinking, when asked to solve the problem we’re facing in this piece, we could write a simple code that looks like this:
const someDelay = 10 * 1000
async function doSomeWork(record: Record): Promise<void> {
console.log("We're doing work on record")
}
async function iterate(records: Record[]): Promise<void> {
for (const record of records) {
await retryWithExponentialBackoff(doSomeWork, record)
await new Promise((resolve) => {
setTimeout(resolve, someDelay)
})
}
}
Although the code above does what’s required, it wouldn’t be suitable for processing big sets of data. For the sake of the argument let’s assume that iterating over our dataset would take 2 months given we can process only 1 record every 10 seconds. If we wanted to proceed with the code above for some reason, we could launch it using an EC2 instance. However, there are two shortfalls to this approach:
-
It’s costly. The bigger the dataset, the higher the cost of running the instance.
-
There is no way of fixing mistakes while the code is doing its job. And what we would like is the ability to update the code as much as needed and have it resume where it left off.
In order to finish our task in the most efficient way, we have to look for a better solution.
AWS tools come in handy
There is an AWS feature called Step Functions that seems to be a very good fit for solving our issue. When implementing it we would create a graph like this one:
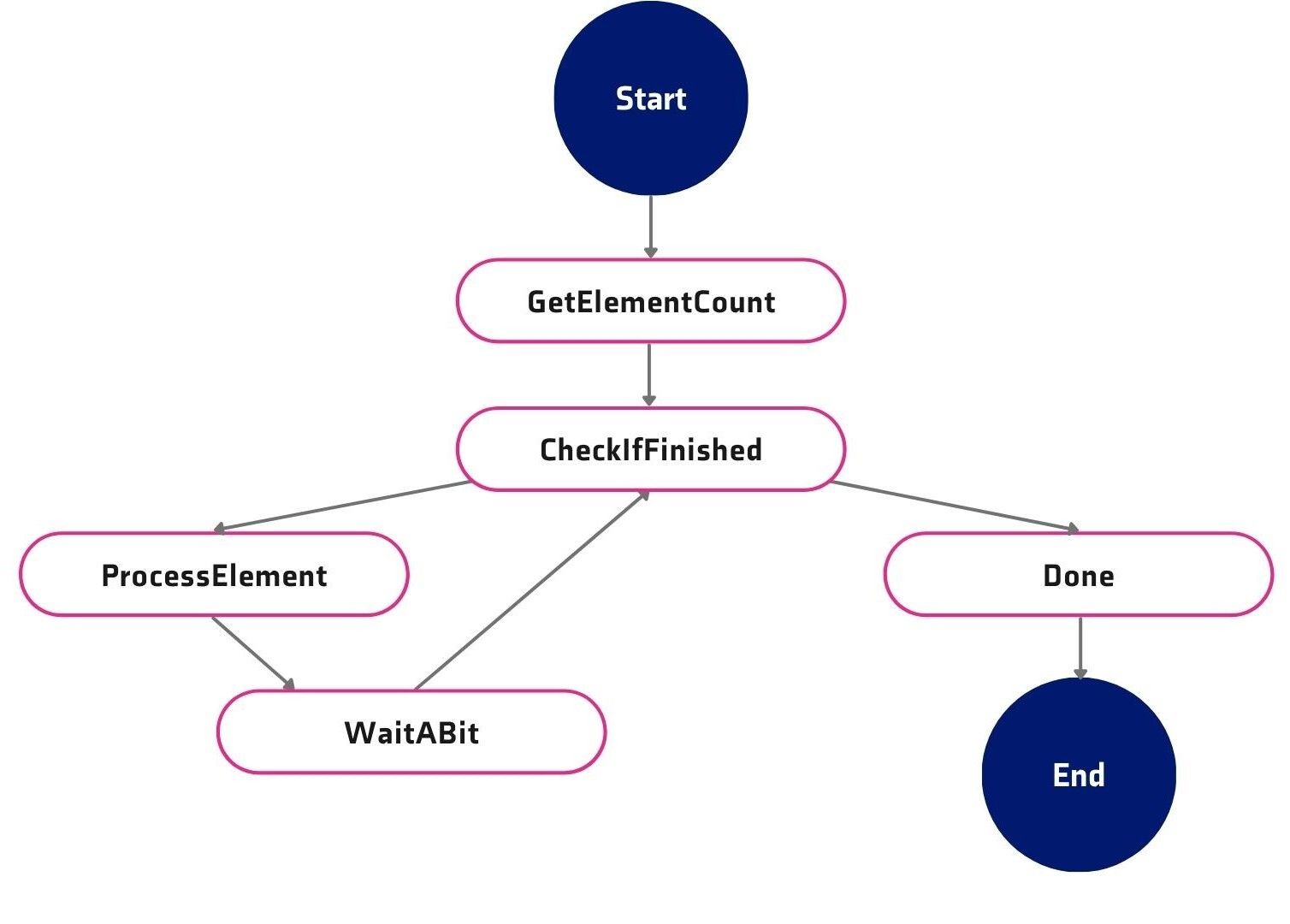
The complete code for this example is located in the template.yml file in this repository. Here is the source of the execution flow:
Definition:
StartAt: GetElementCount
States:
GetElementCount:
Type: Task
Resource: !GetAtt InitIterator.Arn
ResultPath: '$.iterator'
Next: CheckIfFinished
CheckIfFinished:
Type: Choice
Choices:
- Variable: '$.iterator.continue'
BooleanEquals: true
Next: ProcessElement
Default: Done
ProcessElement:
Type: Task
Resource: !GetAtt ProcessElement.Arn
ResultPath: '$.iterator'
Next: WaitABit
Retry:
- ErrorEquals:
- States.TaskFailed
IntervalSeconds: 3
MaxAttempts: 65535
BackoffRate: 1.5
WaitABit:
Type: Wait
Seconds: 10
Next: CheckIfFinished
Done:
Type: Succeed
The code uses two Lambda functions: the first one prepares the iterator object that will be passing along and which will control our process of iteration. It looks like this:
exports.handler = (event, context, callback) => {
console.log(event)
callback(null, {
count: event.collection.length,
index: 0,
continue: event.collection.length > 0,
})
}
The idea here is that as long as $.iterator.continue is true, the iteration will keep on going. The second function is the one actually doing the job. Here’s how it looks:
exports.handler = (event, context, callback) => {
const element = event.collection[event.iterator.index]
console.log({ msg: 'Processing element', element })
callback(null, {
count: event.iterator.count,
index: event.iterator.index + 1,
continue: event.iterator.index < event.iterator.count,
})
}
One can do whatever processing is needed here. As long as this function returns an updated state of the iterator, we’re good to go. It’s important to note that if this function raises an exception, it’s configured to keep on trying until it passes. This part of the configuration (template.yml) is responsible for the behavior:
Retry:
- ErrorEquals:
- States.TaskFailed
IntervalSeconds: 3
MaxAttempts: 65535
BackoffRate: 1.5If you reach an element that for some reason couldn’t be processed, you can always update the code, redeploy, and it will continue the iteration using the new, updated code lines.
Key takeaways
After performing the entire iteration process, let’s look a bit closer at the results. From logs in the Cloud Watch, we know that it’s actually one execution environment that’s doing all the processing. Because of that, we have a long-living node.js process, so whatever we cache in memory can be used between the iteration cycles. And AWS only bills us for the execution time of the iteration, not for the time we wait between them.
As an attentive reader, you probably noticed that in our example we’re passing an entire collection in parameters of the processing function and only select the record to process inside the function. It’s a simplification made for educational purposes and certainly not the right way to proceed if the database in question has over 500k records. The single important bit in the processing is the iterator object. The collection we iterate is usually kept in some sort of database - it doesn’t matter which one is your favorite.
We hope that our little tutorial and the tools we provide will be useful in your projects. In case of questions, we’re here for you - drop us a line!
Bonus: Resources that will help you along the way
When working with Step Functions it's extremely helpful to use the Simulator:https://us-east-1.console.aws.amazon.com/states/home?region=us-east-1#/simulator
It's very useful in understanding how the data flows through the state machine and what values to put in:
-
InputPath
-
OutputPath
-
ResultPath
-
Parameters
Recent posts







